我们在使用soogorfactory采集内容时,经常处理好几百个.csv文件。我们整理了一个我们经常使用的代码分享大家
我们在爱站或5118下载的关键词文件为.csv的,如果我们手动去处理几百个文件,效率慢,还废血条,所以我们就写了个python代码来处理来批处理一下,代码如下:

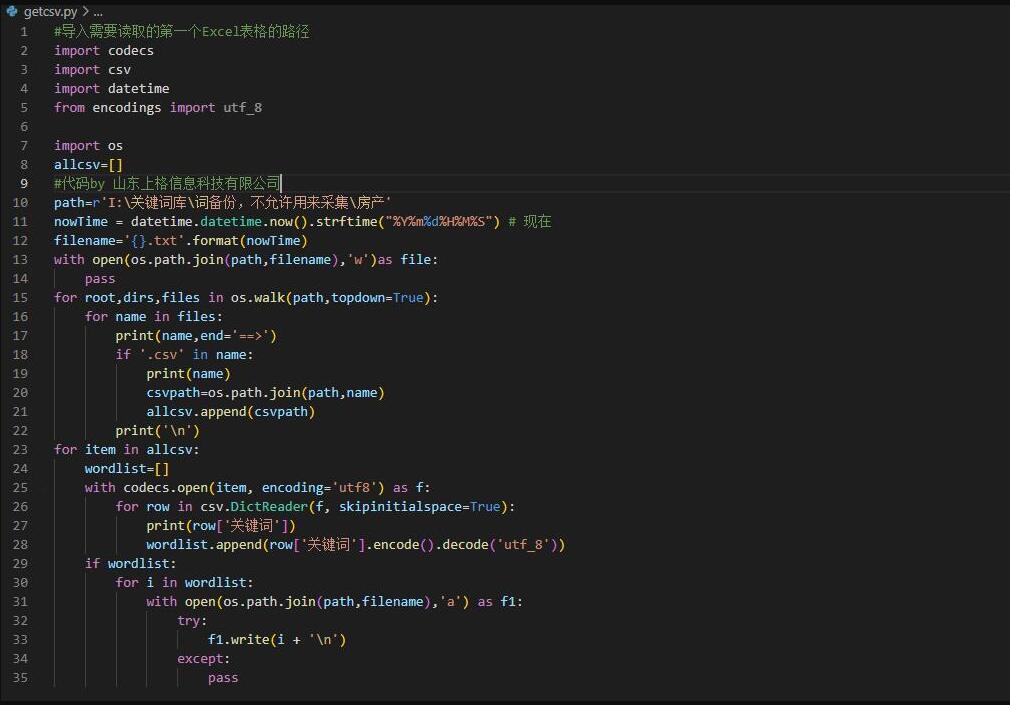
path=r'I:\关键词库\词备份,不允许用来采集\房产'
上面的path为目标文件夹,处理完成后该文件夹下会多一个以时间戳命名的txt文件
#导入需要读取的第一个Excel表格的路径
import codecs
import csv
import datetime
from encodings import utf_8
import os
allcsv=[]
path=r'I:\关键词库\词备份,不允许用来采集\房产'
nowTime = datetime.datetime.now().strftime("%Y%m%d%H%M%S") # 现在
filename='{}.txt'.format(nowTime)
with open(os.path.join(path,filename),'w')as file:
pass
for root,dirs,files in os.walk(path,topdown=True):
for name in files:
print(name,end='==>')
if '.csv' in name:
print(name)
csvpath=os.path.join(path,name)
allcsv.append(csvpath)
print('\n')
for item in allcsv:
wordlist=[]
with codecs.open(item, encoding='utf8') as f:
for row in csv.DictReader(f, skipinitialspace=True):
print(row['关键词'])
wordlist.append(row['关键词'].encode().decode('utf_8'))
if wordlist:
for i in wordlist:
with open(os.path.join(path,filename),'a') as f1:
try:
f1.write(i + '\n')
except:
pass